We are halfway through 2026. Almost every industrial plant on earth is covered in smart sensors.
Billions have been spent on IoT deployments. Accelerometers strapped to every secondary pump. Millions of terabytes of operational data funnelled into cloud dashboards.
And yet, unplanned downtime still costs global industry more than $1.5 trillion a year.
If industrial operations have more data than at any point in history, why are plants still grinding to a halt? Why does the typical maintenance manager still get woken up by an emergency call at 2am?
The answer is one that most IoT vendors do not advertise: sensor monitoring is not the same as machine intelligence. And in 2026, the gap between the two is costing industrial operations far more than the sensors themselves ever saved.
Why Does Sensor-Based Maintenance Fail Despite All the Data?
The failure of sensor-based maintenance is not a hardware problem. It is an intelligence problem.
Most industrial IoT deployments were sold on a straightforward premise: install sensors, collect data, prevent failures. The logic was sound. The execution produced something different — facilities drowning in data but starving for usable insight.
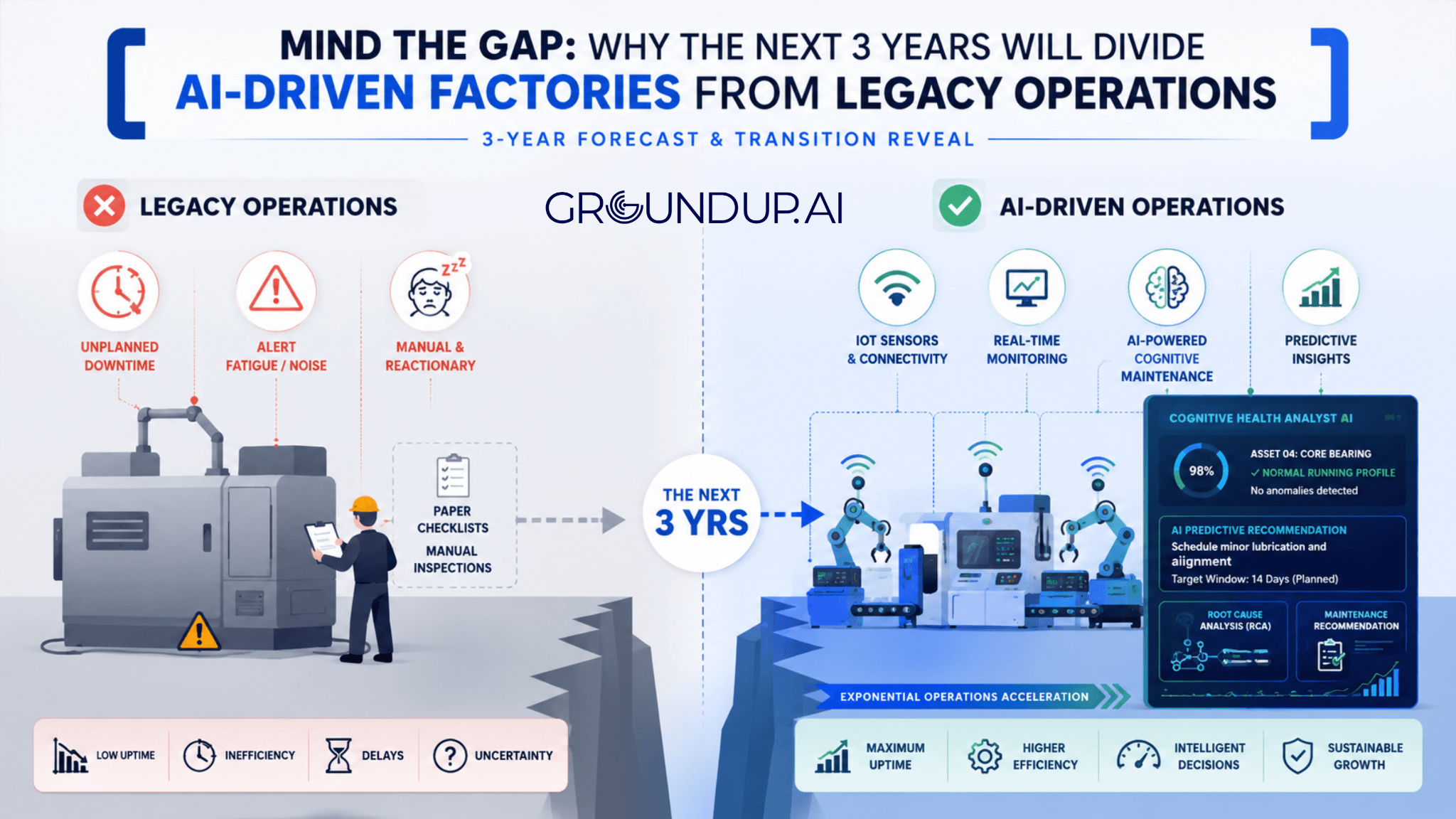
When hundreds of vibration and temperature sensors are installed across a facility, what you actually get is a continuous stream of alarms. “Bearing 4 temperature is up 3%.” “Pump B vibration has crossed baseline threshold.” “Compressor C pressure is fluctuating.” To a software platform without operational context, every anomaly looks like a crisis. Every deviation from baseline triggers an alert.
To an experienced reliability engineer on the floor, this noise produces one predictable outcome: alert fatigue. When everything is flagged as urgent, nothing is. Critical failure warnings get buried under mountains of low-severity notifications. Engineers learn, through repeated experience, that most alerts are false positives — and they begin to treat all alerts accordingly.
The system was installed to prevent failures. The failure it produced was in the system itself.
What Is Alert Fatigue in Industrial Maintenance and How Do You Fix It?
Alert fatigue in industrial maintenance is the condition that develops when maintenance teams receive more alarms than they can meaningfully investigate — and respond by deprioritising or ignoring the alert system entirely.
It is one of the most common and least discussed failure modes of IoT and predictive maintenance deployments. And it is almost entirely caused by systems that lack the contextual intelligence to distinguish between genuine mechanical faults and operational noise.
A machine running hotter because it is under a heavy production load is not failing. A machine running hotter because a bearing is degrading is. To a threshold-based monitoring system, these two scenarios are identical — both cross the temperature limit, both generate an alert. The system cannot tell the difference. The engineer is left to investigate both, wasting time on the first to catch the second.
The fix is not fewer sensors or lower sensitivity thresholds. The fix is context-aware AI that understands what normal looks like for a specific machine under specific operating conditions — and only surfaces anomalies that represent genuine mechanical deviation from that baseline.
When alerts are filtered to only what genuinely matters, engineers stop ignoring the system. Trust is rebuilt. And the warnings that do surface get acted on immediately, because every one of them is real.
Why Do Static Thresholds Fail in Predictive Maintenance Systems?
Static thresholds — fixed limits that trigger an alert when temperature, vibration, or pressure exceeds a set value — are the architectural foundation of most legacy predictive maintenance systems. They fail for two reasons that are fundamental, not incidental.
The first is the “too late” problem. By the time a physical parameter like temperature or structural vibration crosses a high threshold, the component is already severely damaged. The bearing is not developing a fault — it has one. The threshold did not predict the failure. It detected the failure in progress. The alert is a lagging indicator masquerading as a leading one.
The second is the environmental problem. Machines operate in highly dynamic conditions that static thresholds cannot account for. A cement crusher operating in a dusty, high-ambient-heat quarry in Western Australia produces sensor readings that would trigger critical alerts on a system calibrated for a climate-controlled packaging line in a Singapore FMCG facility — even when both machines are operating perfectly normally.
Geography, ambient temperature, production load, asset age, and operational cycle all affect what “normal” looks like for a specific machine in a specific environment. A threshold that signals failure in one context is baseline operating behaviour in another. Without dynamic, context-aware boundaries that adapt to the actual operating environment of each individual asset, predictive maintenance systems produce noise, not intelligence.
What Is the Diagnosis Gap in Industrial Maintenance AI?
The diagnosis gap is the space between an anomaly alert and a usable maintenance action — the investigative work that happens between “something is wrong” and “here is what to do about it.”
Traditional sensor systems close the first problem — they detect that a machine is behaving abnormally. They leave the second problem entirely to the maintenance team. When a conveyor belt sensor flags a sudden vibration spike, the system stops there. Your technicians halt production, open the machine casing, and spend hours determining whether the root cause is particulate contamination, subsurface fatigue in the inner ring, lubricant starvation, or an electrical fault.
The alert delivered a signal. The diagnosis still consumed hours of skilled labour and kept an asset offline for the duration.
In 2026, this is no longer an acceptable architecture for maintenance AI.
A world-class maintenance programme requires automated root cause analysis — not just anomaly detection. The difference in practice looks like this:
Legacy system alert: “Asset 04: High Vibration.”
Cognitive Maintenance diagnosis: “Asset 04 is exhibiting early-stage inner-race bearing wear consistent with lubrication starvation. Schedule a replacement within 14 days and check lubrication alignment before the next shift.”
The first tells you something is wrong. The second tells you what is wrong, why it is happening, and what your team should do about it before the shift ends. The investigation step is eliminated. The maintenance team executes instead of deliberating.
That difference — between detection and diagnosis — is where the real ROI of industrial AI lives.
Why Does Legacy System Fragmentation Undermine Equipment Reliability?
Legacy system fragmentation is the condition most mature industrial facilities have accumulated over decades of piecemeal technology investment — and it is one of the most significant barriers to achieving genuine equipment reliability.
Walk into any established manufacturing plant, naval engine room, or water utility. You will not find a unified monitoring architecture. You will find a 20-year-old compressor sitting next to a brand-new turbine, running on three different SCADA networks, with five different OEM-specific monitoring applications and maintenance logs that still live on clipboards or in spreadsheets that no one updates consistently.
Legacy sensor programmes fail in this environment because they cannot bridge these silos. Vibration data lives in one application. Temperature data lives in another. Maintenance history is in a third system, if it is digitised at all. Without interoperability across these sources, pattern recognition across assets is impossible — and the cross-domain correlation that produces the most valuable diagnostic insights simply cannot happen.
A lubrication-related vibration anomaly that appears minor in isolation looks completely different when correlated with a recent maintenance log entry showing the asset was last serviced six months overdue. The first system sees a threshold crossed. The unified system sees a developing failure.
True equipment reliability in complex industrial environments requires a non-invasive unifying layer — one that sits above any machine regardless of age, brand, or OEM and translates fragmented operational data into a single, coherent picture of asset health. The integration challenge is not incidental. It is where most IoT deployments quietly fail.
What Actually Solves the Sensor Paradox in Industrial Maintenance?
The sensor paradox — more data, same downtime — is not solved by adding more sensors. It is solved by pairing the right signals with AI that reasons rather than just monitors.
Three capabilities separate maintenance programmes that work from those that generate expensive noise.
Pre-trained asset intelligence. Waiting months to accumulate enough historical failure data to train a model is a structural barrier that most industrial deployments cannot absorb. A platform built on a deep library of pre-trained industrial machine signatures — thousands of distinct failure patterns developed across real-world deployments at scale — recognises abnormalities from day one of deployment. The AI knows what a failing bearing sounds like because it has encountered that exact signature across hundreds of other assets in other facilities. Your machine benefits from the collective diagnostic experience of every deployment that came before it.
Acoustic-first sensing as a leading indicator. Vibration and temperature are lagging indicators — they register a fault after it has already developed to a detectable physical level. Sound is a leading indicator. Machines change their acoustic signature at the exact moment something begins to go wrong internally — micro-friction, lubricant breakdown, early-stage component wear — weeks before thermal or vibration sensors register any change. Industrial-grade acoustic sensing captures faults at the earliest possible intervention point, when repair is simplest and cheapest.
Prescriptive action, not just detection. The AI should not function as a sophisticated alarm system. It should function as a digital co-pilot — one that provides maintenance crews with clear, prioritised, actionable repair guidance that turns every technician into a diagnostic expert regardless of their experience level. The output is not a flag. It is an instruction.
Frequently Asked Questions: Sensor-Based Maintenance Failures
Why does predictive maintenance still fail if we have sensors everywhere? Because sensors collect data — they do not interpret it. Without AI that can filter operational noise, adapt to environmental context, and diagnose root causes rather than just detect anomalies, sensor data produces alert fatigue rather than reliability. The hardware is not the bottleneck. The intelligence behind it is.
What is the difference between predictive maintenance and cognitive maintenance? Predictive maintenance uses sensor data and historical patterns to detect when a fault may be developing. Cognitive Maintenance goes further: it diagnoses what the fault is, determines the root cause, and delivers specific actionable recommendations. The difference is the elimination of the human investigation step between alert and action — which is where most of the time, cost, and risk in predictive maintenance programmes actually lives.
How do you fix alert fatigue in an industrial IoT deployment? By replacing static threshold alerting with context-aware AI that understands what normal looks like for each specific asset under its specific operating conditions. When alerts are filtered to only genuine mechanical faults — not environmental variation or load-related deviation — engineers stop ignoring the system. Every alert that surfaces is worth acting on.
Why do static thresholds fail in predictive maintenance? Static thresholds are calibrated for a generic asset in generic conditions. Real machines operate in specific environments with specific load profiles and specific wear histories. A threshold that signals failure in one environment is normal operating behaviour in another. Thresholds also detect failures after they have already developed to a physically measurable level — making them lagging indicators rather than the predictive tools they are sold as.
What does a Cognitive Maintenance alert look like compared to a standard sensor alert? A standard sensor alert tells you a parameter has exceeded a limit. A Cognitive Maintenance diagnosis tells you which specific fault is developing, what is causing it, and what your team should do about it within what timeframe. In practice: “Asset 04: High Vibration” versus “Asset 04 is exhibiting early-stage inner-race bearing wear consistent with lubrication starvation — schedule replacement within 14 days.” The first requires investigation. The second enables immediate action.
How does Cognitive Maintenance handle fragmented legacy systems? Through a non-invasive integration layer that sits above existing SCADA networks, OEM monitoring applications, and operational data sources regardless of their age or format. The goal is not to replace existing systems but to unify the data they produce into a single coherent view of asset health — enabling the cross-domain correlation that fragmented systems cannot produce independently.
Sensors are eyes and ears. Without a brain interpreting what they see and hear, they are expensive noise generators.
The organisations closing the gap on the $1.5 trillion unplanned downtime problem are not the ones adding more hardware. They are the ones building intelligence into the systems they already have. ⚡️