
The standard for success in industrial plants used to be simple: how fast can you fix a broken machine?
That standard is gone.
We are moving out of the era of fast repairs and into the era of complete predictability. And according to the people actually running these facilities, the window to make that transition is shorter than most leaders think.
Mr. Cong Tran, a veteran plant manager with nearly two decades of experience, said it plainly in a recent Groundup.ai fireside chat:
If in another 5 years — we don’t even need to talk about somewhere that far, just 3 years — those factories that do not use AI versus the factories that do use AI, there will be a very clear gap between them.
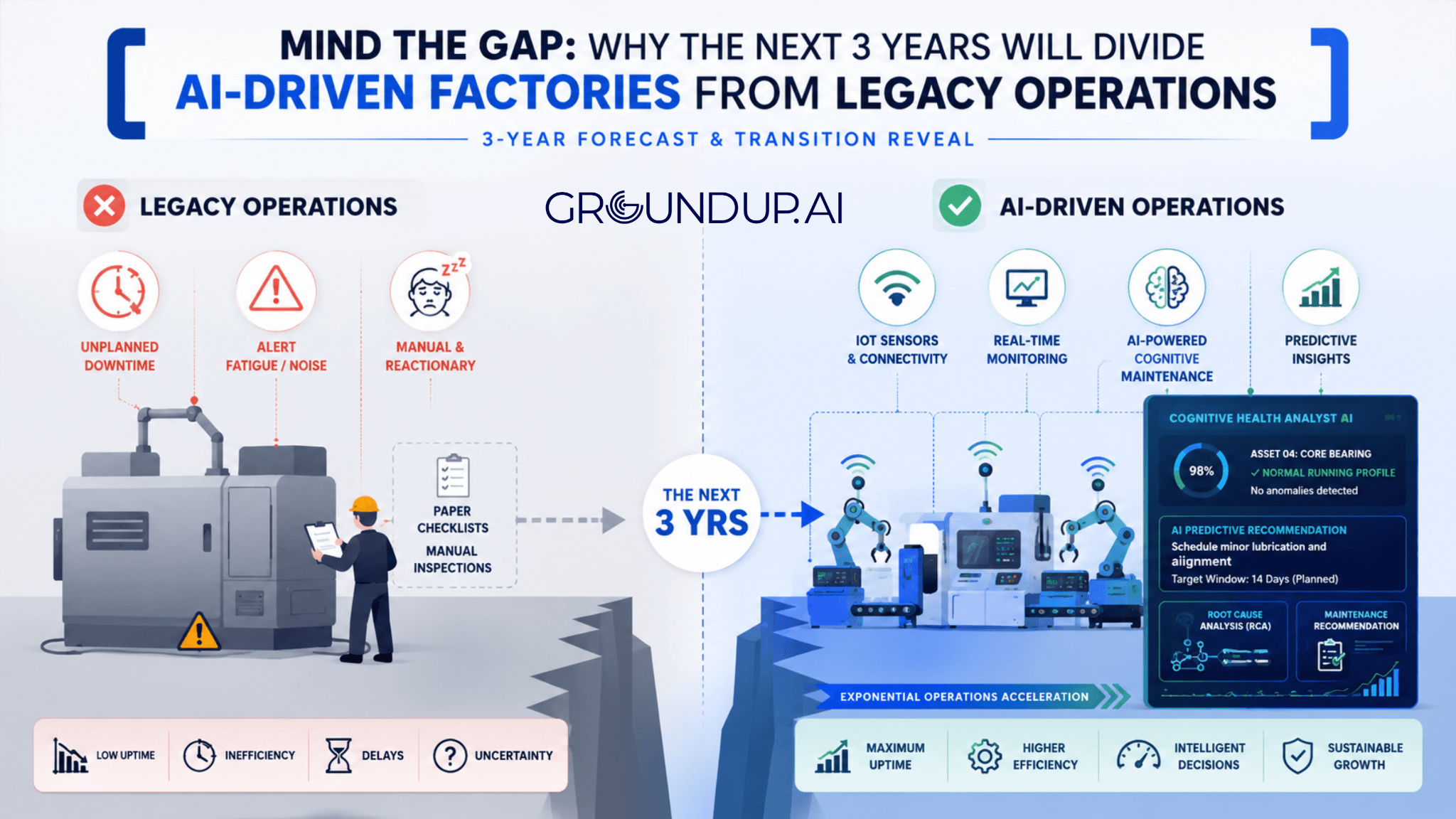
Three years. Not a decade. Not a distant strategic horizon. Three years, and the gap is already opening.
Why Is the Gap Between AI-Driven and Legacy Factories Opening So Fast?
The speed of this divide is not driven by technology alone. It is driven by compounding operational advantage.
Factories that deploy intelligent maintenance AI today are building something that legacy operations cannot replicate quickly: a continuously learning model of their own assets. Every fault detected, every repair executed, every anomaly pattern identified adds to that model. The AI gets more accurate. The operation gets more predictable. The cost of failure drops.
Legacy operations running on manual PM checklists, physical logbooks, and spreadsheet-based downtime tracking are recording history. They are not building foresight. Every month that passes without intelligent asset visibility is a month of compounding exposure; to unplanned failures, to reactive costs, and to the talent drain that comes from maintenance teams permanently stuck in firefighting mode.
That gap does not stay static. It compounds. And once it opens wide enough, it does not close.
What Does Reactive Maintenance Actually Cost a Manufacturing Facility?
Most facilities underestimate the true cost of reactive maintenance because they measure the wrong things.
The visible costs are the spare part, the repair labour, and the downtime hours. These appear in maintenance budgets and get tracked in work order systems. They are real costs, BUT they are not the largest ones.
Mr. Cong described a high-speed production line running at 1,200 units per minute where a simple misalignment in a bottle-capping mechanism escalated silently over a weekend shift. By Monday morning, the bearing was gone, and so was the entire gear assembly.
The real cost: 48 hours of unplanned downtime, over 3 million units in lost production capacity, and emergency air-freight fees that tripled logistics spend just to hit delivery windows.
The spare part was not the expense. As Mr. Cong summarised: “The most expensive thing isn’t the spare part. It is what you lose when you fail to address a problem at the exact right time.”
The fully loaded cost of a single reactive failure typically includes:
- Lost throughput at margin, on every unit that was not produced during the downtime window. For high-volume FMCG lines, this number is almost always larger than the direct repair cost.
- Secondary damage to adjacent components. A fault left unaddressed does not stay contained. It migrates. A misaligned shaft damages the bearing. The bearing failure damages the gear assembly. The gear assembly failure takes the line down. Each escalation step multiplies the repair cost.
- Emergency logistics premium. Expedited parts shipping and contractor call-out rates in an emergency carry a significant premium over planned procurement. This cost rarely appears in maintenance budgets but consistently appears in P&L reviews.
- Customer and contractual consequences. Missed delivery windows trigger penalties, erode client relationships, and in some sectors create regulatory exposure. These costs are real but almost never attributed back to the maintenance failure that caused them.
What Is Alert Fatigue and Why Does It Undermine Predictive Maintenance?
Alert fatigue is the condition that develops when a maintenance team receives more alarms than they can meaningfully act on, and begins to treat all alarms as background noise.
It is one of the most common and least discussed failure modes of early IoT and predictive maintenance deployments.
Standard threshold-based systems trigger an alarm the moment a variable like temperature or vibration exceeds a fixed limit. The problem is that these systems cannot distinguish between a machine running hot because it is under a heavy load, operating in a high-ambient environment, or genuinely developing a fault. All three look identical to a threshold rule. All three generate the same alarm.
The result is a maintenance team that has learned, through experience, that most alarms are false positives. They deprioritise them. They queue them for review at the end of the shift. They develop informal filters based on intuition rather than data.
And then, occasionally, one of those deprioritised alarms is real. And by the time it surfaces as a priority, the fault has already cascaded.
Alert fatigue does not mean the technology failed. It means the technology was not sophisticated enough to do what it promised. The fix is not more alarms. It is smarter filtering. AI that understands context well enough to surface only the anomalies that actually matter.
Why Has Predictive Maintenance Reached Its Structural Limits?
Traditional predictive maintenance (PdM) was a significant advance on reactive and scheduled maintenance. It introduced data-driven visibility into asset health and gave maintenance teams advance warning of developing faults.
But it has a structural ceiling, and most organisations running mature PdM deployments have hit it.
The ceiling is the human diagnosis gap.
A predictive system detects that an asset is behaving abnormally. It generates a warning. An engineer stops what they are doing, investigates the asset, and manually determines whether the root cause is a worn bearing, a misaligned shaft, a lubrication issue, or an electrical fault. The AI did the detection. The human still does the diagnosis.
In a fast-moving manufacturing environment, that manual diagnosis phase consumes time that an at-risk asset cannot afford. It also reintroduces the human variability that predictive maintenance was supposed to eliminate.
Mr. Cong described this directly:
Engineers often have to rely on gut feelings, telling their bosses ‘I feel like this is vibrating too much or getting too hot.’ AI changes that by delivering concrete numbers. It analyses the frequency data month-over-month and shows clear, unarguable trends so managers can make crisp, confident decisions.
The shift from gut feeling to data-driven decisiveness is not an incremental improvement. It is a different operating model.
What Is Cognitive Maintenance and How Is It Different from Predictive Maintenance?
Cognitive Maintenance is the next stage of the maintenance maturity curve; the point at which industrial AI moves from detecting anomalies to reasoning about them.
Where predictive maintenance stops at detection, Cognitive Maintenance continues into diagnosis, root cause analysis, and actionable recommendation; automatically, without requiring a human investigation step in between.
In practice, the difference looks like this:
A predictive system generates an alert: “Asset 04: High Vibration.”
A Cognitive Maintenance platform generates a diagnosis: “Asset 04 is exhibiting early-stage inner-race bearing wear. Schedule a replacement within the next 14 days and check the lubrication alignment.”
The alert tells your team something is wrong. The diagnosis tells them what is wrong, why it is happening, and what to do about it. The investigation step is eliminated. Your team executes instead of deliberates.
The downstream effects of this shift are material:
- Faults captured weeks in advance are resolved during planned maintenance windows. The production line keeps running. Secondary damage to adjacent components is prevented. Emergency logistics costs disappear.
- Safety risk drops because catastrophic mechanical failures are identified and addressed before they become physical events. Maintenance teams are no longer scrambling, they are executing planned work with full information.
- And critically, Cognitive Maintenance filters context the way experienced engineers do. A machine running hotter because of ambient temperature or heavy load does not trigger a false alarm. Only genuine mechanical defects surface, which means every alert the system generates is worth acting on.
What Will Industrial Maintenance Look Like by 2028?
Between now and 2028, industrial maintenance will undergo a transition that has no real precedent in recent manufacturing history.
Advanced AIoT sensors tracking tri-axial vibration, high-frequency acoustics, and localised thermography will become standard across tier-1 and tier-2 assets. The data these sensors generate will be processed not by siloed dashboards requiring manual interpretation, but by specialised industrial AI models trained on thousands of distinct machine behaviours.
Maintenance will become autonomous, hyper-localised, and deeply integrated with overall factory execution systems. The question of whether an asset needs attention will be answered before anyone has to ask it.
The barrier to entry for this transition has already dissolved. Groundup.ai’s AI models pre-trained on over 5,000 distinct industrial machines mean turnkey deployment takes 2 to 3 weeks (not the six-month data collection runway most operations leaders assume). Asset health insights at up to 92+% accuracy from week three of deployment.
The factories that make this transition in the next 36 months will not simply be more efficient than their competitors. They will be operating in a fundamentally different category, one where unplanned downtime is an anomaly, not a baseline expectation, and where every maintenance decision is grounded in data rather than intuition.
Frequently Asked Questions: AI-Driven Factories vs Legacy Operations
How quickly can a manufacturing facility transition from reactive to cognitive maintenance? With pre-trained AI models and wireless IoT sensor deployment, active asset monitoring can begin within 2 to 3 weeks. The transition does not require a multi-year programme. It requires a decision and a starting point.
What is the difference between predictive maintenance and Cognitive Maintenance? Predictive maintenance detects anomalies and generates alerts. Cognitive Maintenance detects anomalies, diagnoses root causes, and delivers specific actionable recommendations, eliminating the human investigation step between alert and action. The result is a compressed decision cycle and a significantly higher proportion of faults that are fully resolved rather than temporarily managed.
What does a Cognitive Maintenance alert actually look like compared to a standard PdM alert? A standard PdM alert tells you an asset has exceeded a threshold. A Cognitive Maintenance alert tells you which specific fault is developing, what is causing it, and what your team should do within what timeframe. The difference is the difference between a warning light and a diagnosis.
How do factories eliminate alert fatigue from IoT maintenance systems? Alert fatigue is eliminated by replacing threshold-based alerting with context-aware AI that filters environmental and operational variables before surfacing an alarm. A machine running hotter under heavy load is not a fault. A machine running hotter with a degrading bearing signature is. Cognitive Maintenance distinguishes between the two. Standard threshold systems do not.
What is the ROI of deploying cognitive maintenance in a manufacturing facility? ROI varies by asset scale, sector, and current maintenance maturity; but the calculation should account for the full loaded cost of unplanned downtime, not just direct repair spend. That includes lost throughput at margin, secondary damage costs, emergency logistics premium, and customer consequence costs. Facilities with high reactive maintenance ratios typically see payback within 12 months of deployment.
The factories that invest in Cognitive Maintenance now will not be waiting to see the gap. They will be on the right side of it. ⚡️
👉 Watch the full webinar video here to future-proof your operations









